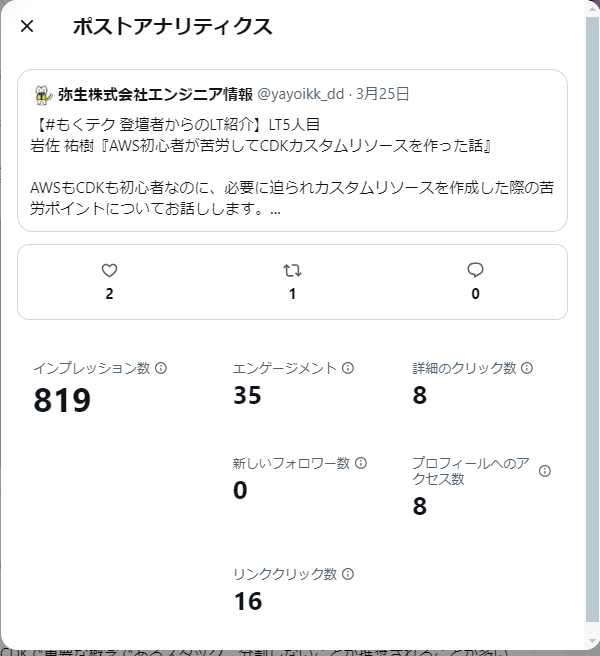
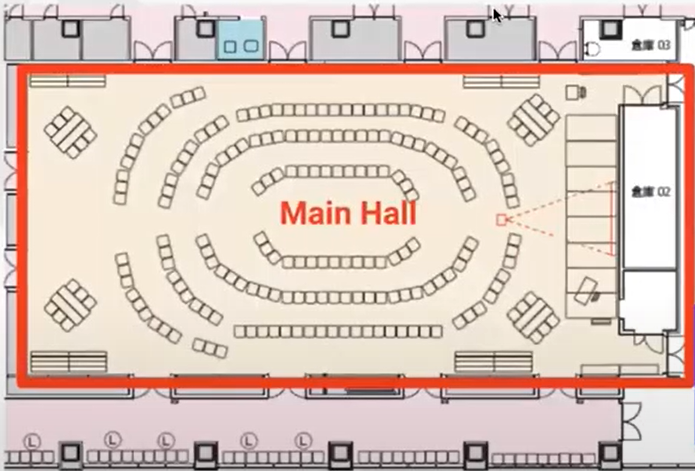
こちらのイベントでは、普段からIaC(Infrastructure as Code)でインフラ構築しているエンジニアに登壇してもらい、LTで知見を共有してもらいました。
また、後半はLTで登壇したメンバーに再び登壇してもらい、パネルディスカッションの形で、IaCについて用意したテーマについて語ったり、本番中に参加者から寄せられた質問に回答したりしました。
「Women in Agile Tokyo 2024に参加」で1記事にしようと思ったのですが、いろいろと書きたいことが出てきたので、記事を分けることにしました。 tech-blog.yayoi-kk.co.jp
「Womenについて考えてみた編」を書いて1か月ほど経ちました。今回は、「学び持ち帰ってやってみたこと編」です。
こんにちは、カトです。
2024年2月6日Women in Agile Japan 開催のWomen in Agile Tokyo 2024にオンサイト参加してきました。 www.wiajapan.org
弥生では女性リーダーの育成を掲げ、リーダーの割合に目標値を設定しています。
確かに女性リーダーの割合が少ない部署があったり、社内役員に女性がいなかったりといった現状はあります。 note.yayoi-kk.co.jp1年ほど前、2023年4月に公開された弥生公式note記事です。サムネイル画像に写っているのは男性。
弥生に限ったことではなく、どこの組織やチームにおいても、リーダーや役員をやりたい人が、女性という理由だけでその役割ができない、やりにくいのであれば変えなければいけません。
しかし、本当にそうなのでしょうか?性別問わず希望する仕事に就けることは重要だろうとは思います。
一方で、チームメンバーの構成、就業者、リーダーの人数、あらゆる男女比を1:1にしようとすることは、他の歪を生むことになるのではないだろうか?と考えていました。
そんな中「Women in Agile Japan」の開催を知りました。
アジャイルを推進するのにMenもWomenも関係ないだろうと思いながらも、せっかくの機会だから参加してみることにしました。
開催前日、東京では珍しく雪が降りました
今回、Women in Agile Tokyo 2024に参加して、「Women」に対して偏見や特別視をしていた自分に気がつくことができました。
全体を通して
WomenをターゲットにしたAgileの集まりに懐疑的だった私ですが、非常に充実したのしい1日を過ごしました。
Womenという会なのだから、おそらくほとんどが女性を自認する人があつまっているのだろうと考えていました。
実際には、参加者の比率は男女比は半々程度とのことでした。
イベントの終盤に「Womenとイベントタイトルをつけて、Womenをターゲットにして呼びかけてようやく女性が半分なのか」と感じたのですが、主催者から「Women in Agile Japan の実行委員としては男性の参加を呼び掛けてきました。ジェンダーギャップを生み出しているマイクロアグレッションなどの問題を考えるときに、男性や現行のマネジメント層の理解が重要になるからです。」というコメントをいただきました。